前回に続き二元配置分散分析(two-way ANOVA)。

データの準備
繰り返しのある二元配置分散分析としてこちらのデータを使用する。
要素1:a, b, c
要素2:A, B

分散分析表の概要
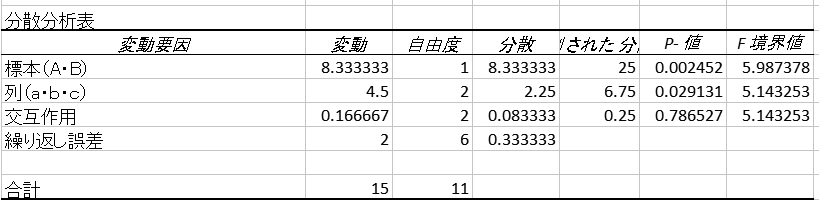
分散分析の結果として上記の様な表が得られるが、今回はそもそもこの分散分析、何をしているかというところを説明したい。
まず使用するデータについて、全体の平均と標本・列・交互作用・誤差の効果に分解した下記のような式を考える。

細かい計算は後の記事で解説するとして、実際の数字としては下記のようになる。

そしてそれぞれの効果の二乗和を取ったものが「変動」で、それをそれぞれの自由度で割ったものが「分散」になる。
さらに、標本・列・交互作用の分散を誤差の分散で割ったものが「観測された分散比」であり、誤差に対して各効果が十分大きいか、という判断が出来る。これがF検定と呼ばれるものである。
各効果を図にするとこんな感じで、標本や列の効果は誤差に比べて大きそうで、交互作用は小さそうだという事が見て取れる。
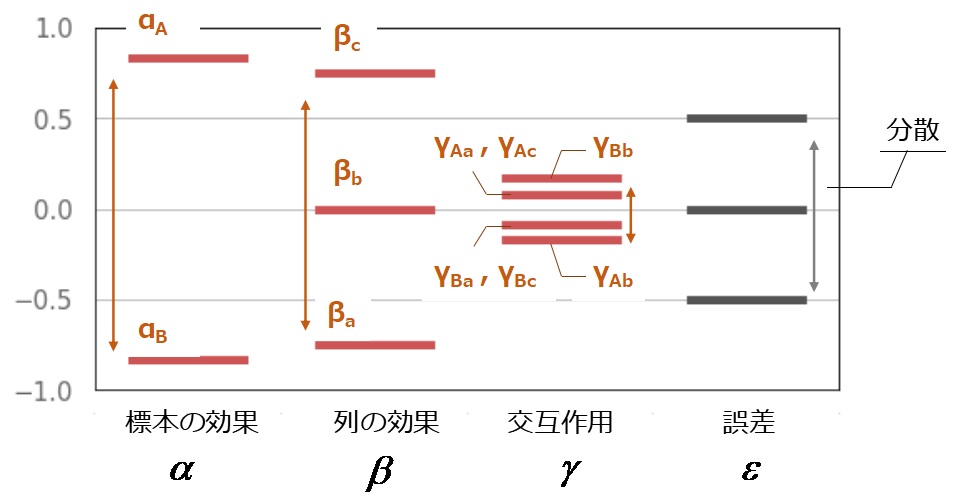
それぞれの分散を取ることで効果の大きさを定量的に評価することが出来る。
例えば標本(A・B)の違いがデータに大きな影響を及ぼすとすれば、と
の差が大きく、分散は大きくなるはずである。
ざっくりとした解説はこの程度にして、次からは具体的な計算を行っていく。