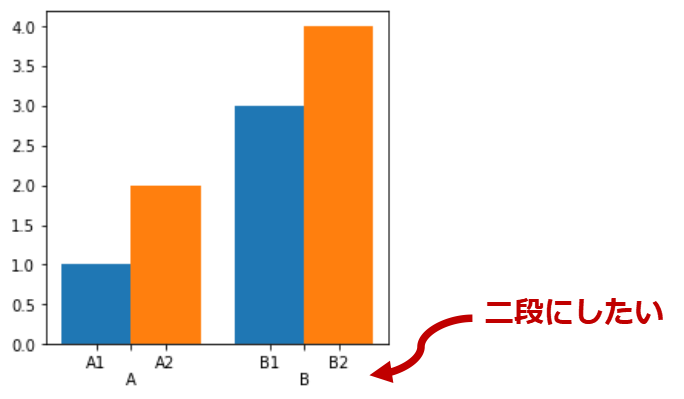
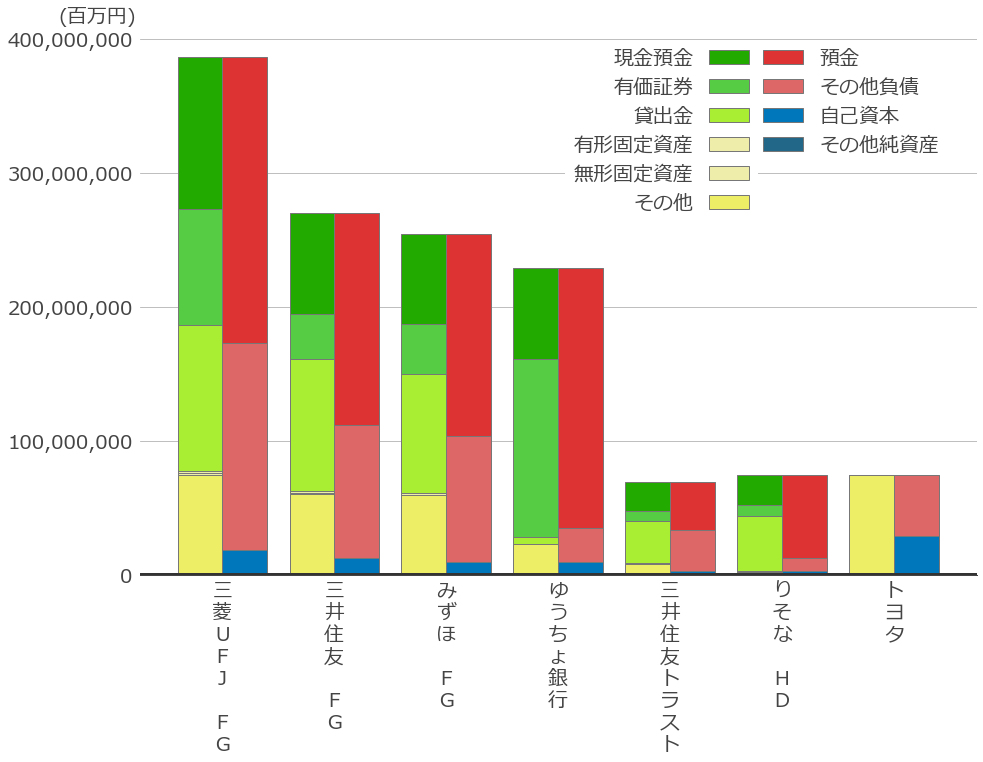
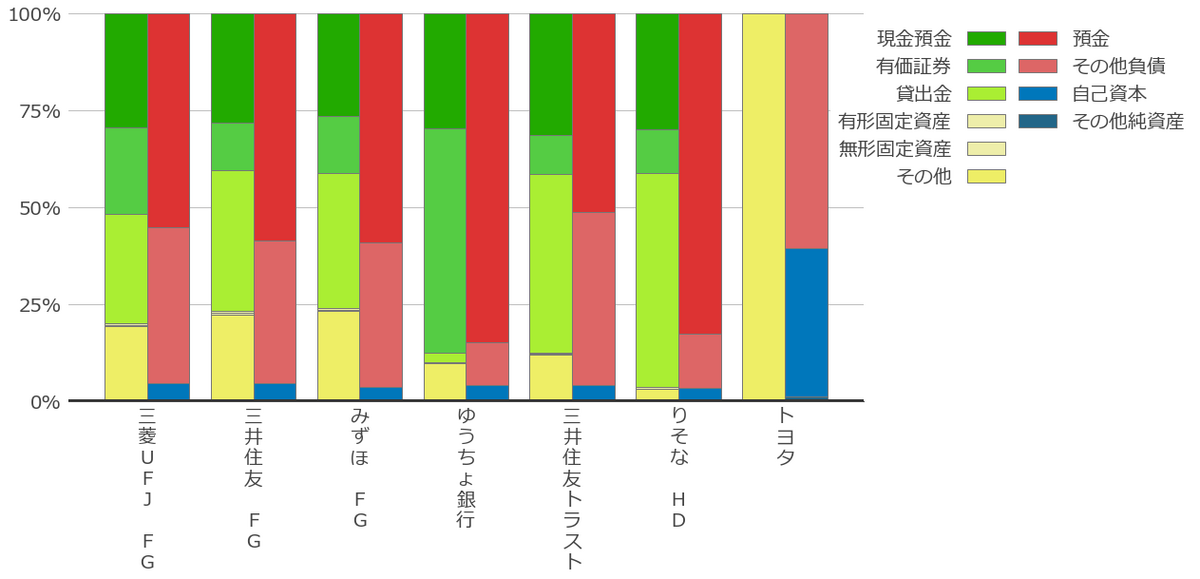
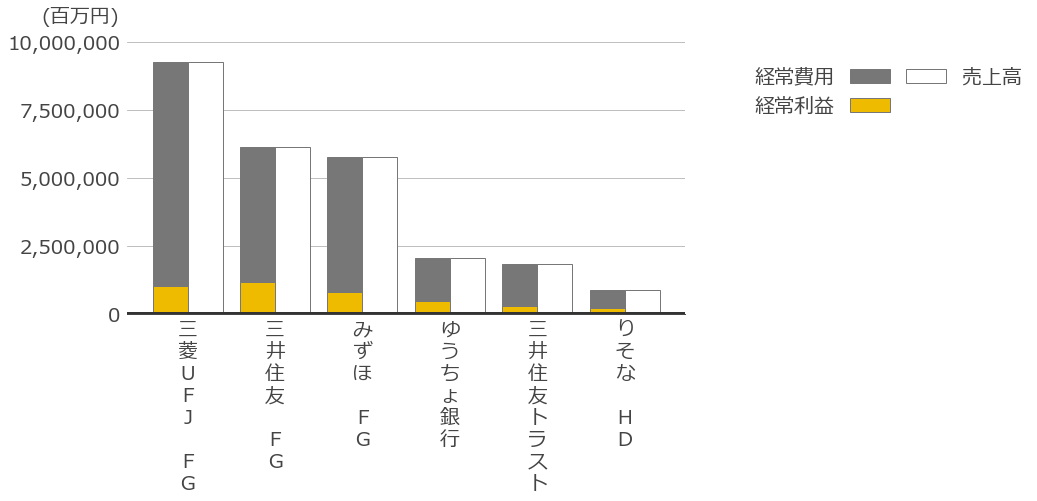
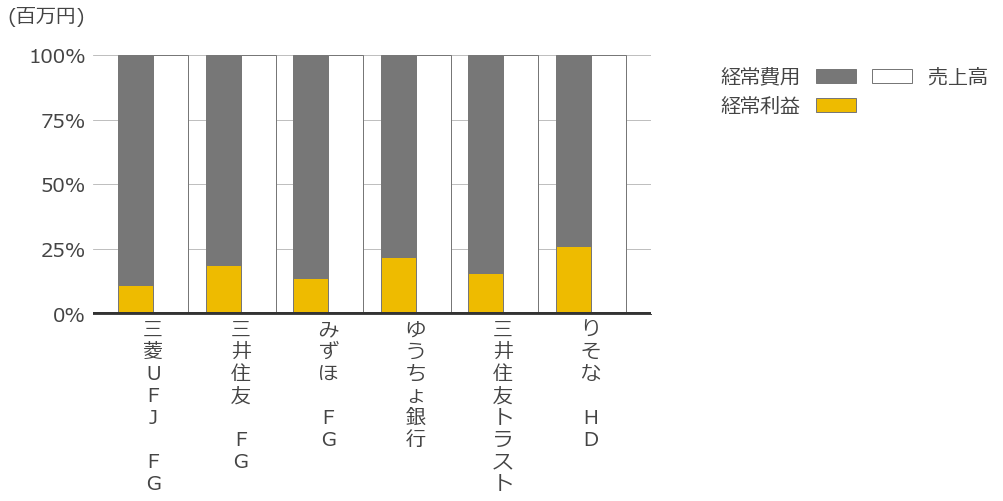
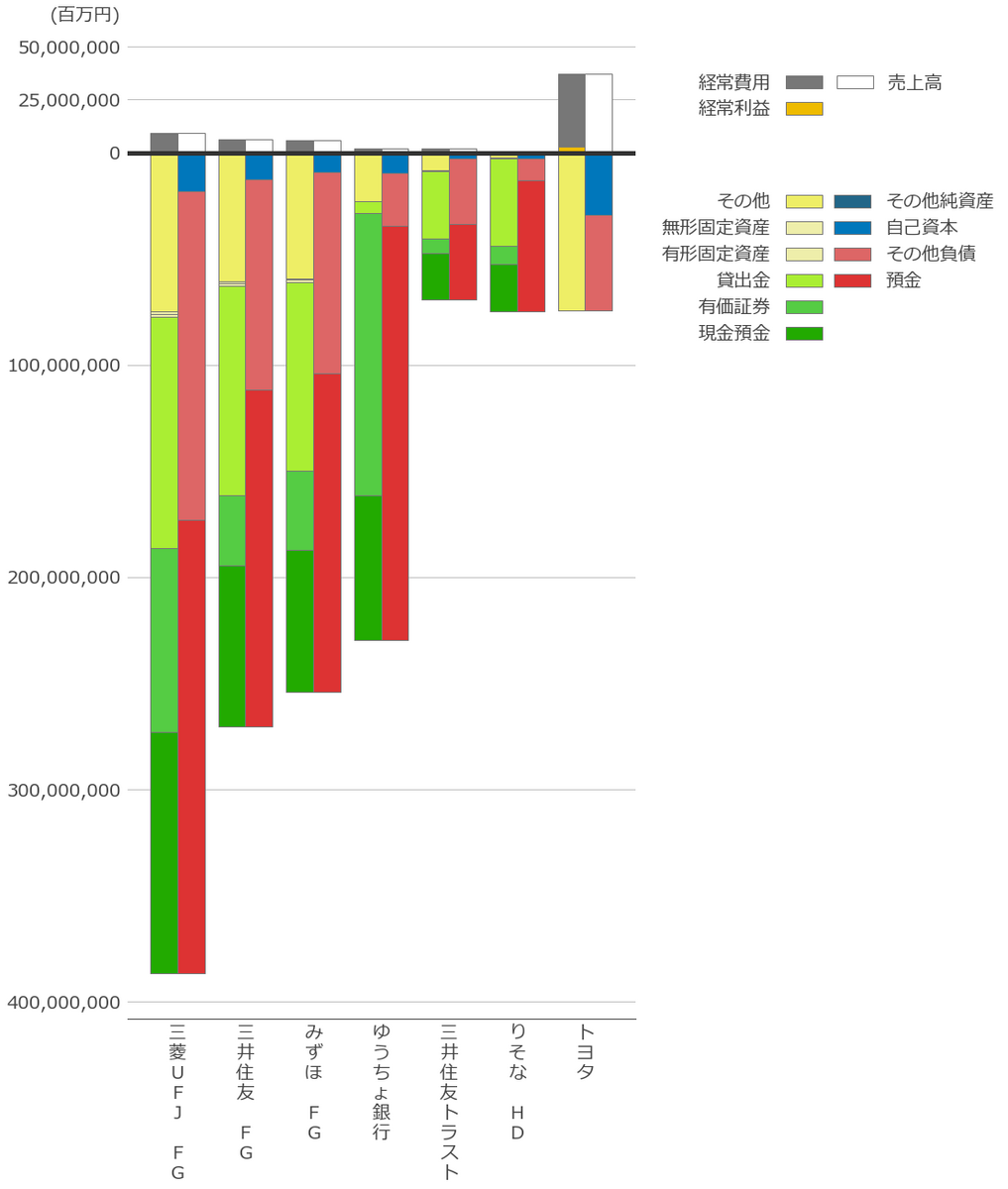
最近キャッシュフロー計算書を眺めていて、各社のキャッシュフローをウォーターフォールチャートで作りたくなった。
またも非常に長いコードになったが一応求めていた仕上がりにはなったと思う。
これを作るために2週間くらいかかってしまった・・・。これでようやく企業間の比較が出来る・・・

import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
import matplotlib.patheffects as patheffects
s_text_s = 12
s_text_m = 15
color_r = "#dd3333"
color_b = "#0077bb"
color_gr = "#aaaaaa"
color_gr2 = "#555555"
fig_x = 10
fig_y = 5
font = 'Meiryo'
bar_w = 0.15
space = 1.2
label_offset = 80
w_spine = 1
w_plot = 1
y_ticks = [0,1000,2000]
y_ticks_l = [0,1000,2000]
def tategaki(labels):
new_labels = []
for n in labels:
n2 = '\n'.join(n.replace("ー", "|"))
new_labels.append(n2)
return new_labels
data = {
'先期末残高': [1000, 500],
'営業CF': [500, -300],
'投資CF': [300, -100],
'財務CF': [-200, 200],
'今期末残高': [1600, 300]
}
index = ['A社', 'B社']
df = pd.DataFrame(data, index=index)
ind = np.arange(len(df.columns))
bottom_data = {
'先期末残高': 0,
'営業CF': df['先期末残高'],
'投資CF': df['先期末残高'] + df['営業CF'],
'財務CF': df['先期末残高'] + df['営業CF'] + df['投資CF'],
'今期末残高': 0
}
index = ['A社', 'B社']
bottom_df = pd.DataFrame(bottom_data, index=index)
top_data = {
'先期末残高': df['先期末残高'],
'営業CF': df['先期末残高'] + df['営業CF'],
'投資CF': df['先期末残高'] + df['営業CF'] + df['投資CF'],
'財務CF': df['先期末残高'] + df['営業CF'] + df['投資CF'] + df['財務CF'],
'今期末残高': df['今期末残高']
}
index = ['A社', 'B社']
top_df = pd.DataFrame(top_data, index=index)
bar_x_df = pd.DataFrame(index=df.index, columns=df.columns)
for i in range(len(bar_x_df)):
for j in range(len(bar_x_df.columns)):
bar_x_df.iloc[i, j] = i + (j -2) * bar_w * space
colors_df = df.applymap(lambda x: color_b if x >= 0 else color_r)
colors_df.iloc[:, [0]] = color_gr
colors_df.iloc[:, [-1]] = color_gr2
offset_df = df.applymap(lambda x: 1 if x >= 0 else -1) * label_offset
fig = plt.figure(figsize=(fig_x,fig_y), facecolor="white")
ax1 = fig.add_subplot(111)
plt.rcParams['font.family'] = font
for n in df.columns:
ax1.bar(bar_x_df[n],
df[n],
bottom=bottom_df[n],
width=bar_w,
color=colors_df[n]
)
for m in np.arange(len(df[n])):
ax1.text(bar_x_df[n][m],
top_df[n][m] + offset_df[n][m],
f"{int(df[n][m]):,}",
ha='center', va='center',
color=colors_df[n][m],
fontsize=s_text_s,
path_effects=[patheffects.withStroke(linewidth=4, foreground='white', capstyle="round")]
)
for n in np.arange(len(df.columns)-1):
ax1.plot([bar_x_df.iloc[:,n] - bar_w * 0.5,
bar_x_df.iloc[:,n+1] + bar_w * 0.5],
[top_df.iloc[:,n],
top_df.iloc[:,n]],
color=color_gr,
linewidth=w_plot
)
list_xpos = bar_x_df.values.flatten().tolist()
list_xpos.extend(np.arange(len(df))+0.000001)
list_xlabel_text=list([])
list_xlabel_size=list([])
for n in np.arange(len(df)):
list_xlabel_text.extend(df.columns)
list_xlabel_size.extend([s_text_s]*len(df.columns))
list_xlabel_text.extend("\n\n\n"+df.index)
list_xlabel_size.extend([s_text_m]*len(df.index))
list_xlabel_text = tategaki(list_xlabel_text)
ax1.tick_params(axis='x', which='both', bottom=False, top=False)
ax1.set_xticks(list_xpos)
xticklabels = ax1.set_xticklabels(list_xlabel_text, color=color_gr2)
for label, size in zip(xticklabels, list_xlabel_size):
label.set_fontsize(size)
ax1.set_yticks(y_ticks, color=color_gr)
ax1.set_yticklabels(y_ticks_l, fontsize=s_text_m, color=color_gr2)
ax1.grid(axis="y")
ax1.tick_params(axis='both', which='both', bottom=False, top=False, left=False, right=False)
ax1.yaxis.set_major_formatter(plt.FuncFormatter(lambda x, loc: "{:,}".format(int(x))))
fig.text(0.09, 0.93, '(百万円)', ha='center', va='center', color=color_gr2 , fontsize= s_text_m)
ax1.spines['top'].set_linewidth(0)
ax1.spines['bottom'].set_linewidth(w_spine)
ax1.spines['bottom'].set_color(color_gr)
ax1.spines['left'].set_linewidth(0)
ax1.spines['right'].set_linewidth(0)
ax1.set_axisbelow(True)
plt.show()