Cmdstanpyでベイズ推定を実行した後に、summary()を実行すると各種パラメーターのまとめが出てくるが、その中に予測区間がある。
デフォルトは5%,50%,95%だが、この予測区間の範囲を変更したくなった。
fit.summary()
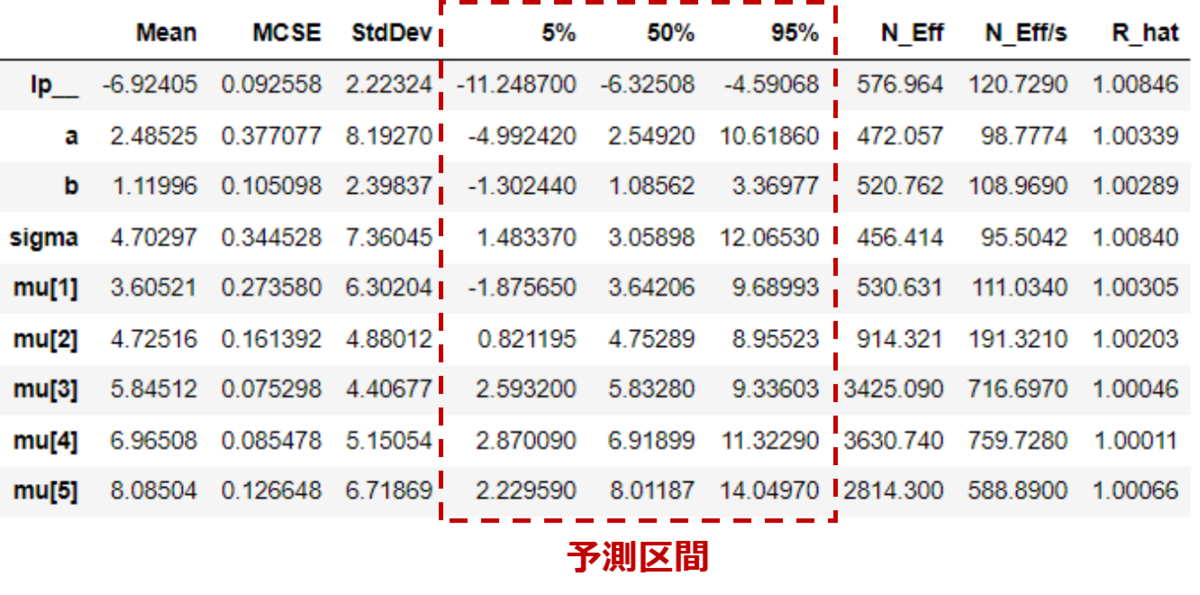
percentilesで指定するといいらしく、範囲も変更できるし出力する数も変更することが出来た。
fit.summary(percentiles=(1,2.5, 50, 97.5,99))
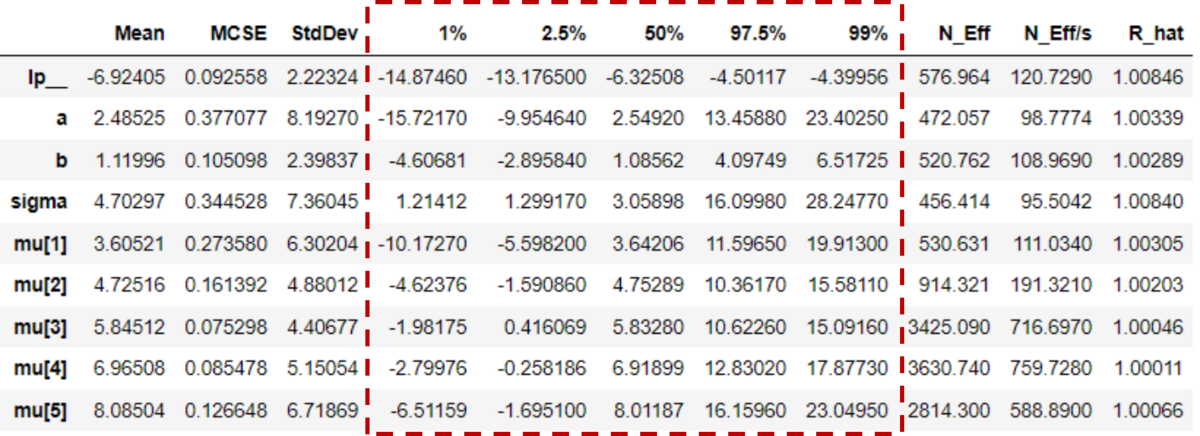
全体のコードはこちら。
pythonコード
import os import time import numpy as np import arviz as az from matplotlib import pyplot as plt from cmdstanpy import CmdStanModel #データを作成 x = np.array([1, 2, 3, 4, 5]) y = np.array([2, 6, 6, 9, 6]) #stanファイルをコンパイル stan_file = "./test_1.stan" exe_file = "./test_1" if not os.path.exists(exe_file): model = CmdStanModel(stan_file=stan_file) else: model = CmdStanModel(exe_file=exe_file) data = { "N": len(x), "X": x, "Y": y } import multiprocessing num_cpu = multiprocessing.cpu_count() fit = model.sample( data=data, chains=4, # chain数 seed=1, # seed固定 iter_warmup=1000, # warmupの数 iter_sampling=2000, # samplingの数 parallel_chains=num_cpu, # 並列数 save_warmup=True, # warmupもCSVに保存 thin=1, # サンプリング間隔 #output_dir=output_dir, # 出力先 show_console=False, # 標準出力 show_progress=True # progress出力 )
fit.summary()
stanコード(XとYを実数のグループで指定)
data {
int<lower=0> N; //データ数
vector[N] X;
vector[N] Y;
}
parameters {
real a;
real b;
real<lower=0> sigma;
}
transformed parameters{
vector[N] mu;
mu = a + b*X;
}
model {
Y ~ normal (mu, sigma);
a ~ normal(0, 1000);
b ~ normal(0, 1000);
}